实战与基本原理
实战与基本原理
# 使用场景
# 日志收集
通过kafka以统一接口服务的方式开放给各种consumer
# 消息系统
解耦和生产者和消费者、缓存消息等
# 用户活动跟踪
Kafka经常被用来记录web用户或者app用户的各种活动
# 运营指标
Kafka也经常用来记录运营监控数据
# 基本概念
- 一个分布式的,分区的消息(官方称之为commit log)服务
- Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
- 服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
# 相关术语
# message
基础的消息(Message),生产消费的基本单位。
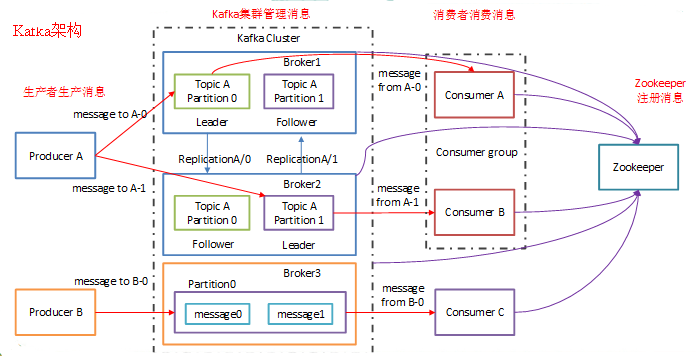
# Broker
消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
# Topic
Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
# Producer(生产者)
消息生产者,向Broker发送消息的客户端
# Consumer(消费者)
消息消费者,从Broker读取消息的客户端
# ConsumerGroup
每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息
# Partition(分区)
- 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的
- 逻辑上topic的下一级,kafka为了提高吞吐量和可用性,会把一类消息分成多个区存储。
- topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。同一个partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
# replica (副本)
- kafka为了实现高可用,会对partition(分区)保存多个replica(副本),存在的唯一理由就是为了实现消息的高可靠存储,不让消息丢失。
- 其中又分leader 副本和follower副本,follower同步leader副本,leader副本宕机时,从剩余follower副本中选出一个作为新的leader 副本,实现高可用(一个partition的多个副本一定不会在同一个broker上)。
# Leader
- 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
- Leader和Follower都是针对Partition,来说的。
# Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
# Offset
消息位移值一共有两种:
- 第一种是分区内的每条消息都有一个位移值,代表每条消息在文件中的位置,offset从0到消息数量-1,就好比数组的下标。
- 第二种相对于kafka消费端而言的offset,代表了消费端当前的读取进度,比如消费端offset为3,代表消费者已经消费到了第四条消息。
kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
# ISR (in-sync replica,与leader replica保持同步的replica集合)
kafka会为每一个partition动态维护一个replica集合,该集合中的replica存储的所有消息日志与leader replica保持同步状态,如果因为网络延迟等原因部分ISR中的replica消息同步进度落后leader replica太多,则会将该replica踢出ISR,等后续追上进度时kafka再将其自动加入ISR。
# kafka基本使用 (opens new window)
- 安装
- 发消息
- 消费消息
# 主题Topic和消息日志Log
- 可以理解Topic是一个类别的名称,同类消息发送到同一个Topic下面。对于每一个Topic,下面可以有多个分区(Partition)日志文件
- Partition是一个有序的message序列,每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的
- kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响。
- 每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。这意味kafka中的consumer对集群的影响是非常小的,这也是性能高。
# 理解Topic,Partition和Broker
- 一个topic,代表逻辑上的一个业务数据集
- 如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker。partition在不同的broker中都可以为leader
# 为什么要对Topic下数据进行分区存储
- commit log文件会受到所在机器的文件系统大小的限制
- 为了提高并行度
# 集群
- broker.id属性在kafka集群中必须要是唯一,对应连接的zookeeper必须相同
- kafka将很多集群关键信息记录在zookeeper里,保证自己的无状态,从而在水平扩容时非常方便。
# 集群消费
# 流程
- leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果,不提供读写(主要是为了保证多副本数据与消费的一致性)。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。
- 生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。
# Consumers传统的消息传递模式
- queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。所有的consumer都位于同一个consumer group 下。
- publish-subscribe模式:消息会被广播给所有的consumer。所有的consumer都有着自己唯一的consumer group。
# 消费顺序问题
- 一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,从而保证消费顺序。
- consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的consumer消费不到消息。
- Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
# java代码
# 参考资料
kafka架构、基本术语、消息存储结构 (opens new window)

Kafka(一)Kafka的简介与架构 (opens new window)